“If they’re too big to fail, they’re too big,”
2009/10/16
Finally...
2009/10/09
Norwegian Irony?
I like the guy too, but:
I find myself in the bizarre situation of agreeing with crazy right-wing nutcases (not linked to, but depressingly easy to find), terrorists, and a News Corporation talking head, all at the same time. He hasn't done anything yet!!! And in any in any case, torture! Sheesh!
In February, the Obama DOJ went to court to block victims of rendition and torture from having a day in court, adopting in full the Bush argument that whatever was done to the victims is a "state secret" and national security would be harmed if the case proceeded.
[...]
And all year long, the Obama DOJ fought (unsuccessfully) to keep encaged at Guantanamo a man whom Bush officials had tortured while knowing he was innocent.- The indefatigable Glenn GreenwaldAsked why the [nobel] prize had been awarded to Mr Obama less than a year after he took office, Nobel Committee head Thorbjoern Jagland said: "It was because we would like to support what he is trying to achieve"- BBC News- Hamas official Sami Abu Zuhri."Obama has a long way to go still and lots of work to do before he can deserve a reward,""It's the prize for not being George W. Bush"--Sky News commentator.
I find myself in the bizarre situation of agreeing with crazy right-wing nutcases (not linked to, but depressingly easy to find), terrorists, and a News Corporation talking head, all at the same time. He hasn't done anything yet!!! And in any in any case, torture! Sheesh!
2009/10/06
Hotrepart: long term plans
Pace my previous post on moving hotrepart forward, the plan is as follows:
Canvas will probably be fully supported in IE10 by this time. Anyway.
- Patch the seemingly-dormant CloudTools to support PostgreSQL, using Londiste for replication.
- Patch CloudTools again to allow online adding & removing slaves.
- Patch hotrepart and PL/Proxy again, this time to add a CLUSTERS command that will allow PL/Proxy to act as a bus not just for sharding, but also for master-slave replications.
- Patch CloudTools again to allow dynamic repartitioning with hotrepart.
Canvas will probably be fully supported in IE10 by this time. Anyway.
2009/09/06
My WiFi access point.
My Wifi access point used to be open to anyone, with the name "noP2PwebOKthanks". What this meant was that people were free to surf the web, but politely requested not to download movies, films, or anything else that would get me in trouble.
Of course, this didn't work, and after too many times of having slow access to my own connection, and exceeding my bandwidth quota, I added a password. The wifi network is now called "bit.ly/1wflj1", which is a link to this blog post.
If you used to use my network and enjoyed free Internet access for occasional use, then you can still use my wifi - get in touch with me and I'll see what I can do.
Of course, this didn't work, and after too many times of having slow access to my own connection, and exceeding my bandwidth quota, I added a password. The wifi network is now called "bit.ly/1wflj1", which is a link to this blog post.
If you used to use my network and enjoyed free Internet access for occasional use, then you can still use my wifi - get in touch with me and I'll see what I can do.
2009/08/16
You were saying something about 'best intentions'?
Well, hotrepart is my most recent attempt at doing something interesting outside of work, and it took me down some interesting avenues.
I didn't figure that I'd be patching PL/Proxy, learning C, pointer arithletic and memory management along the way. It was interesting working in a bare text editor, but also much, much slower. It took me maybe 40 hours of screen-time and 20 hours of no-screen thinking, spread across about 3 months, to get a 1.1Kloc patch out the door.
Once I did this, I then realised that my plan to scale Postgres to the moon was fundamentally flawed: queries that had to be run across the whole dataset (RUN ON ALL in PL/Proxy parlance) would eventually saturate the cluster without a decent replication system. A decent replication system (that can be automatically installed and reconfigured on-the-fly at runtime) is of course the one thing Postgres lacks right now.
During this three months I also read up more on datacenter-scale applications and Google's concept of the Warehouse Scale Computer, which altered my thinking somewhat.
Motivation
At this point I should explain, to myself if nobody else, why I started this whole experiment. The thinking was that the algorithms behind DHTs and distributed key-value stores like Dynamo should in theory be implementable using RDBMS installs as building blocks. What you lose in performance overhead you gain in query language expressivity. Going further, with a decent programmable proxy it should be possible to route DB requests just like DHTs route pull requests etc. Further still, a "proxy layer" on top of the DB layer should self-heal and use a Paxos algorithm to route around failures and update the routing table.
One of the properties of the hotrepart system as-is is that it is immediately consistent. In theory, the system proposed above would trade that off for eventual consistency, with a lag equal to the replication delay, but gaining partition-tolerance, on the assumption that the replication also had a hot-failover component. Hello, there, Brewer's conjecture.
Needless to say this would be a ridiculous amount of work to implement, even it it worked in theory. Were this to be made real, however, would such a system scale to the numbers obtained with Hadoop? That is the question.
One way to answer it would be to construct a simulation cluster processing requests and then to torture the cluster in various ways (kill hosts, partition the network) and watch what happens. We shall see.
The end result is that hotrepart is stalled for the moment, pending ideas on the direction in which to take it foward. As with Gradient, even if nothing comes of the project, it's still out there in the open. Four years after I stopped work on Gradient it still proved useful to other people because of the ideas alone, and combining XMPP and hypertext is something everyone's doing now, so I don't necessarily think I've wasted my time on this so far.
I didn't figure that I'd be patching PL/Proxy, learning C, pointer arithletic and memory management along the way. It was interesting working in a bare text editor, but also much, much slower. It took me maybe 40 hours of screen-time and 20 hours of no-screen thinking, spread across about 3 months, to get a 1.1Kloc patch out the door.
Once I did this, I then realised that my plan to scale Postgres to the moon was fundamentally flawed: queries that had to be run across the whole dataset (RUN ON ALL in PL/Proxy parlance) would eventually saturate the cluster without a decent replication system. A decent replication system (that can be automatically installed and reconfigured on-the-fly at runtime) is of course the one thing Postgres lacks right now.
During this three months I also read up more on datacenter-scale applications and Google's concept of the Warehouse Scale Computer, which altered my thinking somewhat.
Motivation
At this point I should explain, to myself if nobody else, why I started this whole experiment. The thinking was that the algorithms behind DHTs and distributed key-value stores like Dynamo should in theory be implementable using RDBMS installs as building blocks. What you lose in performance overhead you gain in query language expressivity. Going further, with a decent programmable proxy it should be possible to route DB requests just like DHTs route pull requests etc. Further still, a "proxy layer" on top of the DB layer should self-heal and use a Paxos algorithm to route around failures and update the routing table.
One of the properties of the hotrepart system as-is is that it is immediately consistent. In theory, the system proposed above would trade that off for eventual consistency, with a lag equal to the replication delay, but gaining partition-tolerance, on the assumption that the replication also had a hot-failover component. Hello, there, Brewer's conjecture.
Needless to say this would be a ridiculous amount of work to implement, even it it worked in theory. Were this to be made real, however, would such a system scale to the numbers obtained with Hadoop? That is the question.
One way to answer it would be to construct a simulation cluster processing requests and then to torture the cluster in various ways (kill hosts, partition the network) and watch what happens. We shall see.
The end result is that hotrepart is stalled for the moment, pending ideas on the direction in which to take it foward. As with Gradient, even if nothing comes of the project, it's still out there in the open. Four years after I stopped work on Gradient it still proved useful to other people because of the ideas alone, and combining XMPP and hypertext is something everyone's doing now, so I don't necessarily think I've wasted my time on this so far.
2009/05/27
Finally!
The code that produced the below graph is released! Hotrepart was basically done a month ago, but I decided that releasing code into the wild, especially code that is supposed to start conversations, is probably not the best thing to do at the same time as organising my own wedding. I'm happily married now :-) Hence the release.
This is an ongoing project that I don't intend to let rot, like I did with Gradient. There are several things to do off the bat: another patch to PL/Proxy, then configuring EC2 to run Postgres nicely, then coding up some intelligence to trigger the repartitioning. Amazon releasing autoscaling just made that a whole lot easier.
This is an ongoing project that I don't intend to let rot, like I did with Gradient. There are several things to do off the bat: another patch to PL/Proxy, then configuring EC2 to run Postgres nicely, then coding up some intelligence to trigger the repartitioning. Amazon releasing autoscaling just made that a whole lot easier.
2009/02/01
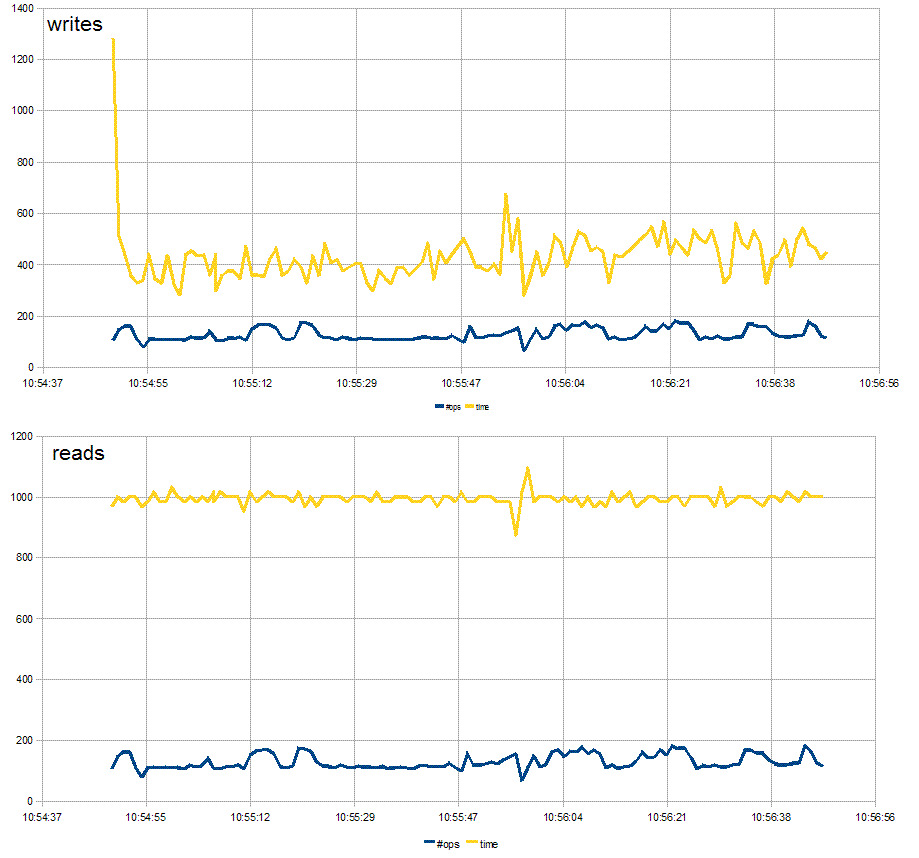
Yay!
The below graphs show two minutes of reads and writes against a PostgreSQL database running inside VMWare on a modern 2-core laptop, with #ops per second and response time plotted in each case. The initial high response time for writes is caused by the connection pool filling.
Half-way through, where the lines spike, the database is split (repartitioned) into two partitions - one being the original, the second newly created that second. Both of the new databases are on the same host, but this is a trivial detail.
More soon :-)

Half-way through, where the lines spike, the database is split (repartitioned) into two partitions - one being the original, the second newly created that second. Both of the new databases are on the same host, but this is a trivial detail.
More soon :-)
2008/12/22
Amazon redux
Y'know, despite all my bloviation over the wonderfulness of AWS, I would be remiss if I failed to mention that Amazon have taken a dent in my estimation recently due to this story by the Times of London documenting work practices which appear to be if not illegal, then at the very least inhumane. I would be surprised if being threatened with dismissal for more than 6 days of illness is acceptable behaviour under UK employment law.
Even though working on AWS would be a dream job, I'm writing this anyway because I don't believe in candy-coating the nature of 'the beast'. Just like individual people, groups of people also have facets of their collective nature that should be lauded, or condemned, and hopefully redeemed.
Not sure if the next batch of presents will come from Amazon.co.uk though.
Update 1 Feb. 2009. The Sunday Times badly misrepresented Google's energy efficiency a while ago, so also took a dent in my estimation of their credibility, so who knows about the above? Maybe it's an equally manufactured controversy.
Even though working on AWS would be a dream job, I'm writing this anyway because I don't believe in candy-coating the nature of 'the beast'. Just like individual people, groups of people also have facets of their collective nature that should be lauded, or condemned, and hopefully redeemed.
Not sure if the next batch of presents will come from Amazon.co.uk though.
Update 1 Feb. 2009. The Sunday Times badly misrepresented Google's energy efficiency a while ago, so also took a dent in my estimation of their credibility, so who knows about the above? Maybe it's an equally manufactured controversy.
Notes on a small proxy, or: "PL/Proxy: lessons learnt, hints and tips"
PL/Proxy is the SQL proxy that Skype released as a part of their open source program. Although in some ways less flexible than MySQLProxy, focused as it is purely on partitioning and load-balancing, it's been used in production under HA circumstances and is definitely production quality code.
I installed it on a Linux image and found the following:
When installing from source:
If the anything changes in your get_cluster_partitions function, then you should also increment the value returned by get_cluster_version. PL/Proxy caches the results of get_cluster_partitions to avoid calling it with every invocation, but on a per-version basis.
While the documentation says "the number of connections for a given cluster must be a power of 2", don't forget that 1 connection is also possible.
You can proxy to a proxy, but there are two things to gake into account:
1) Your reads can't use SELECTs inside your proxy functions, i.e. no "cluster A run on B select C", which is bad style anyway. Instead, your target databases have to have functions with a method signature identical to that of the function on the proxy.
2) It's not much use if you're using a stock PL/Proxy install that uses hashtext with identical cluster-choice logic on both proxies. Why? In this example scenario,
P1 -> part00,
+ -> P2 -> part01, part02
...Nothing will ever be written to p01 - P1 partitions the same way as P2.
According to the todo list, PL/Proxy currently loads response result sets into memory, which leads to some obvious limitations.
CONNECT doesn't take function arguments. This can be emulated by having one-DB clusters, but still.
"Tagged partitions" are not very clear in the docs, and neither is the reason for the restriction on having the number of partitions equal to a a power of 2, but the PL/Proxy FAQ explains this. PL/Proxy uses the lowest N bits of the hash to decide which partition to run on, and N bits has range of 2^N, hence the limitation.
At time of writing, the above FAQ isn't linked to from the Skype project homepage, neither is it in CVS or in the release, but it answers a lot of questions. The other place where a lot of questions are answered is the plproxy-users mailing list, where people have already asked most of the simple questions, and had them clearly answered by the project lead.
I installed it on a Linux image and found the following:
When installing from source:
- On Debian-based systems (including Ubuntu) If you don't have pg_config, you need to install the package postgresql-server-dev-8.X
- Make sure flex & bison are installed first.
- Make sure you have the latest version. Previous versions rely on flex & bison being defined in pg_config, which is not always the case.
If the anything changes in your get_cluster_partitions function, then you should also increment the value returned by get_cluster_version. PL/Proxy caches the results of get_cluster_partitions to avoid calling it with every invocation, but on a per-version basis.
While the documentation says "the number of connections for a given cluster must be a power of 2", don't forget that 1 connection is also possible.
You can proxy to a proxy, but there are two things to gake into account:
1) Your reads can't use SELECTs inside your proxy functions, i.e. no "cluster A run on B select C", which is bad style anyway. Instead, your target databases have to have functions with a method signature identical to that of the function on the proxy.
2) It's not much use if you're using a stock PL/Proxy install that uses hashtext with identical cluster-choice logic on both proxies. Why? In this example scenario,
P1 -> part00,
+ -> P2 -> part01, part02
...Nothing will ever be written to p01 - P1 partitions the same way as P2.
According to the todo list, PL/Proxy currently loads response result sets into memory, which leads to some obvious limitations.
CONNECT doesn't take function arguments. This can be emulated by having one-DB clusters, but still.
"Tagged partitions" are not very clear in the docs, and neither is the reason for the restriction on having the number of partitions equal to a a power of 2, but the PL/Proxy FAQ explains this. PL/Proxy uses the lowest N bits of the hash to decide which partition to run on, and N bits has range of 2^N, hence the limitation.
At time of writing, the above FAQ isn't linked to from the Skype project homepage, neither is it in CVS or in the release, but it answers a lot of questions. The other place where a lot of questions are answered is the plproxy-users mailing list, where people have already asked most of the simple questions, and had them clearly answered by the project lead.
2008/11/27
PostgreSQL:
They try harder. Their help system is on the windows admin client is one of the best I've ever seen. That says "attention to detail". Colour me impressed!
2008/11/13
Unwrapping Oracle wrapped objects in Oracle 10g
Oracle wrapped objects are basically a really weak encryption (backed up, I imagine, by the DMCA or it's local equivalent, and well-paid lawyers), intended to give people who want to 'protect' their IP some sense of false security.
"The oracle hacker's handbook" by David Litchfield explains the scheme as follows:

Of course, this sounds interesting, so the first thing to do is dive into the wrap.exe and see what we can see using REC, which looks to be a pretty neat decompiler.
A quick glance at the function list shows that the routine we're looking for is pki_wrap. Grepping through the Oracle files show that the method's defined in orapls10.[dll/so/whatever], as confirmed by this nifty DLL inspection utility, at which point REC choked on 3.5 MB of object code, and my sorely lacking assembler skills failed me, so no propietary trade secret subsitution table for me today...
"The oracle hacker's handbook" by David Litchfield explains the scheme as follows:

Of course, this sounds interesting, so the first thing to do is dive into the wrap.exe and see what we can see using REC, which looks to be a pretty neat decompiler.
A quick glance at the function list shows that the routine we're looking for is pki_wrap. Grepping through the Oracle files show that the method's defined in orapls10.[dll/so/whatever], as confirmed by this nifty DLL inspection utility, at which point REC choked on 3.5 MB of object code, and my sorely lacking assembler skills failed me, so no propietary trade secret subsitution table for me today...
2008/10/10
Say it loud...
Cory Doctorow:
After announcing that they'd be shutting off their DRM servers and nuking their customers' music collections, Wal*Mart has changed their mind. Now they've told their customers that they'll be keeping these servers online indefinitely -- which means that they'll be paying forever for their mistaken kowtowing to the entertainment industry's DRM mania.All those companies (cough Amazon cough Apple cough) that say they're only doing DRM for now, until they can convince the stupid entertainment execs to ditch it, heed this lesson: you will spend the rest of your corporate life paying for this mistake, maintaining infrastructure whose sole purpose is to lock your customers into a technology restriction that no one really believes in. Welcome to the infinite cost of doing business with Hollywood.
Watching the guys selling DRM being hoist by their own petard, now that the world has moved on, is schadenfreude of the first order...
2008/09/25
2008/09/24
State of play in EC2-based database hosting
Oracle recently blinked and decided to support their DB and some other stuff on EC2. Reading the actual terms though, assuming I've understood them correctly, they haven't actually done anything other than map EC2 virtual cores onto CPU Sockets, and let the normal rates apply. That's IT. What this means is that running one Oracle server for 100 hours is still 100 times more expensive (for licensing costs) than running 100 Oracle servers for one hour.
That's not cloud licensing. Cloud computing works on the premise that whether you use one, 10, or 100 CPUs, you pay per CPU-hour, no more no less. That's what DevPay does. The only problem is that in this scenario, software is a commodity, which I imagine doesn't sit too well with Oracle.
Virtualisation has been around for decades, but only once FLOSS commoditized the server operating system 'ecosystem' did it become possible to do things on the scale that Amazon are doing. Back in 2005 I had a Linux VM with the inestimable Bytemark, and it was plain for all with eyes to see that virtualisation was going to pull the floor out the bottom of the server hosting market once players had found the right way to leverage the economies of scale. Right now, that's being done behind closed doors by the big players, but Amazon are the first to have thrown open the doors to the unwashed masses, and that's why I like them so much.
(To repeat, I don't own stock - maybe I should :-)
To get back to the point. How do databases fare on Amazon EC2? Given that EBS has only been around for a couple of weeks, and before that, on EC2, DB hosting was risking everything to a block device that could go *poof* at any moment, which wasn't exactly pleasant.
This is something which will remain up in the air until someone with serious [PostGre/My]SQL-fu takes some AMIs, configures them just so, and benchmarks them. We know, right now, that on a small instance, disk throughput tops out at roughly 100 MB/s on a three-volume RAID 0 setup. I'm interested in seeing the speeds for EC2 and EBS on larger instances.
Moving on from pure throughput, how do PostGreSQL & MySQL stack up on these setups? Do their respective caching mechanisms etc. work with or against this strange new environment? Enquiring minds want to know!
That's not cloud licensing. Cloud computing works on the premise that whether you use one, 10, or 100 CPUs, you pay per CPU-hour, no more no less. That's what DevPay does. The only problem is that in this scenario, software is a commodity, which I imagine doesn't sit too well with Oracle.
Virtualisation has been around for decades, but only once FLOSS commoditized the server operating system 'ecosystem' did it become possible to do things on the scale that Amazon are doing. Back in 2005 I had a Linux VM with the inestimable Bytemark, and it was plain for all with eyes to see that virtualisation was going to pull the floor out the bottom of the server hosting market once players had found the right way to leverage the economies of scale. Right now, that's being done behind closed doors by the big players, but Amazon are the first to have thrown open the doors to the unwashed masses, and that's why I like them so much.
(To repeat, I don't own stock - maybe I should :-)
To get back to the point. How do databases fare on Amazon EC2? Given that EBS has only been around for a couple of weeks, and before that, on EC2, DB hosting was risking everything to a block device that could go *poof* at any moment, which wasn't exactly pleasant.
This is something which will remain up in the air until someone with serious [PostGre/My]SQL-fu takes some AMIs, configures them just so, and benchmarks them. We know, right now, that on a small instance, disk throughput tops out at roughly 100 MB/s on a three-volume RAID 0 setup. I'm interested in seeing the speeds for EC2 and EBS on larger instances.
Moving on from pure throughput, how do PostGreSQL & MySQL stack up on these setups? Do their respective caching mechanisms etc. work with or against this strange new environment? Enquiring minds want to know!
2008/08/30
Thoughts on Amazon EC2/EBS and the "cloud computing" bandwagon
Amazon EBS is something that I've been waiting for ever since EC2 was announced. Dare Obasanjo rightly pegged it as the final piece of the puzzle.
Right now, "cloud computing" is the buzzword of the moment. This doesn't help create clarity when discussing exactly what it is. So, my definition is:
But nobody has what Amazon has. Want 500 servers for an hour? There's no place else to go but Amazon. So, despite all the hype about cloud computing, right now there's only one real market player that has a developed, mature product, and that is Amazon. Nobody else even comes close, and that includes Google.
(And no, I don't own shares.)
I was reading an article about how MS are basically building their new datacenters around shipping containers full of server kit that were constructed directly by manufacturers in China or thereabouts. I can almost guess they've built a standard umbilical cable & docking mechanism for the containers for power, bandwidth & airco. Roboticise the docking/undocking, then all you'd have to do is have a small control center and a foreman to operate the gantry.
To get all hand-wavey, sci-fi and "thereof I cannot speak with clue" for a minute, assuming the containers are airtight, and given that they'll never be open to humans until it's time to scrap/recycle them, why not look at using CO2 as a coolant instead of standard air conditioning? Automatic fire suppression comes free. And given that CO2 is still a gas at -70°C, why not overclock your CPUs to increase your ROI (of course, the energy you spend on cooling and the reduced lifespan of your CPUs due to overclocking is an opposite factor).
If you scrub the CO2 from the atmosphere, and dispose of it safely, you may even make your datacenter carbon neutral and reap tax credits as an additional benefit... (coming soon to a cognizant country near you.)
Fna fna fna.
Right now, "cloud computing" is the buzzword of the moment. This doesn't help create clarity when discussing exactly what it is. So, my definition is:
- an API to dynamically start, stop & manage instances
- per-CPU-hour and per-GB billing
But nobody has what Amazon has. Want 500 servers for an hour? There's no place else to go but Amazon. So, despite all the hype about cloud computing, right now there's only one real market player that has a developed, mature product, and that is Amazon. Nobody else even comes close, and that includes Google.
(And no, I don't own shares.)
I was reading an article about how MS are basically building their new datacenters around shipping containers full of server kit that were constructed directly by manufacturers in China or thereabouts. I can almost guess they've built a standard umbilical cable & docking mechanism for the containers for power, bandwidth & airco. Roboticise the docking/undocking, then all you'd have to do is have a small control center and a foreman to operate the gantry.
To get all hand-wavey, sci-fi and "thereof I cannot speak with clue" for a minute, assuming the containers are airtight, and given that they'll never be open to humans until it's time to scrap/recycle them, why not look at using CO2 as a coolant instead of standard air conditioning? Automatic fire suppression comes free. And given that CO2 is still a gas at -70°C, why not overclock your CPUs to increase your ROI (of course, the energy you spend on cooling and the reduced lifespan of your CPUs due to overclocking is an opposite factor).
If you scrub the CO2 from the atmosphere, and dispose of it safely, you may even make your datacenter carbon neutral and reap tax credits as an additional benefit... (coming soon to a cognizant country near you.)
Fna fna fna.
Subscribe to:
Posts (Atom)

